输入URL到页面显示全过程解析
总览
网络请求、解析过程、渲染过程、渲染图层笔记
更新时间: 2023/3/14
# URI、 URL 和 URN 的区别
URI Universal Resource Identifier 统一资源标志符
URI采用一种特定语法标识一个资源的字符串。所标识的资源可能是服务器上的一个文件。不过,也可能是一个邮件地址、新闻消息、图书、人名、Internet主机或者任何其它内容。
URL是一种特定形式的URI,它用于指定互联网上资源的位置信息
URI包含URL和URN
URL Universal Resource Locator 统一资源定位符 URL唯一地标识一个资源在Internet上的位置
URN Universal Resource Name 统一资源名称 URN它命名资源但不指定如何定位资源,比如:只告诉你一个人的姓名,不告诉你这个人在哪。例如:telnet、mailto、news 和 isbn URI 等都是URN。
URL 一定是 URI ;URN + URL 就是 URI
url编码默认使用的字符集是US-ASCII。 例如a在US-ASCII码中对应的字节是0x61,那么Url编码之后得到的就是%61,我们在地址栏上输入 http://g.cn/search?q=%61%62%63 ,实际上就等同于在google上搜索abc了,url地址必须都是合法的ASCII码,如果出现中文或者其他非ASCII码会进行编码将其转换为ASCII码。
# 输入URL到页面发生了什么?

# 第一阶段-网络角度
在浏览器输入一个地址例: https://www.baidu.com/
URL解析:
对 URL 进行解析之后,浏览器确定了 Web 服务器和文件名
encodeURIComponent decodeURIComponent主要对传递的参数信息编码
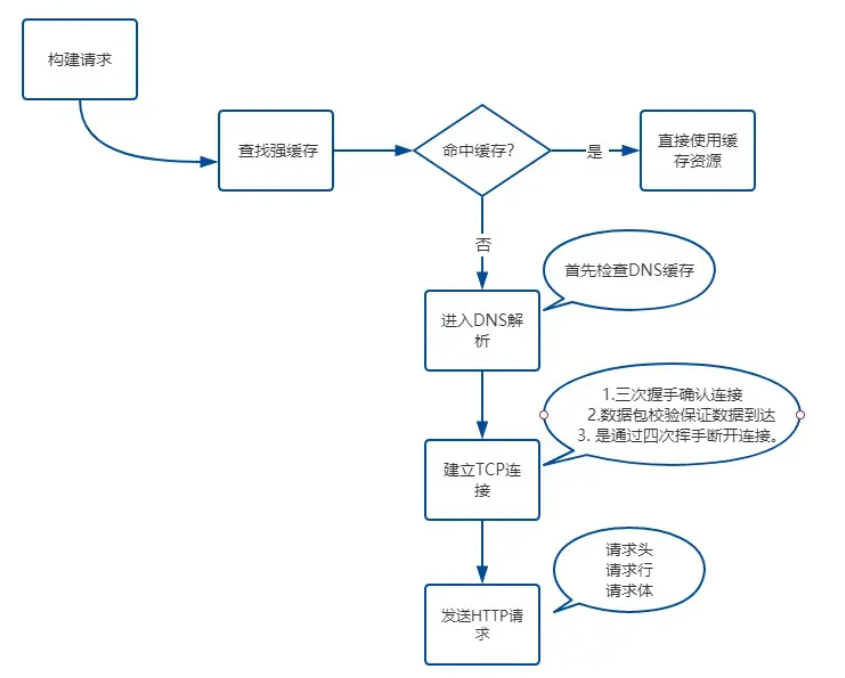
查找缓存
先检查强缓存,如果存在则直接使用,否则再检查协商缓存,如果都没有则进入下一步。具体详细见**浏览器缓存**笔记
DNS解析
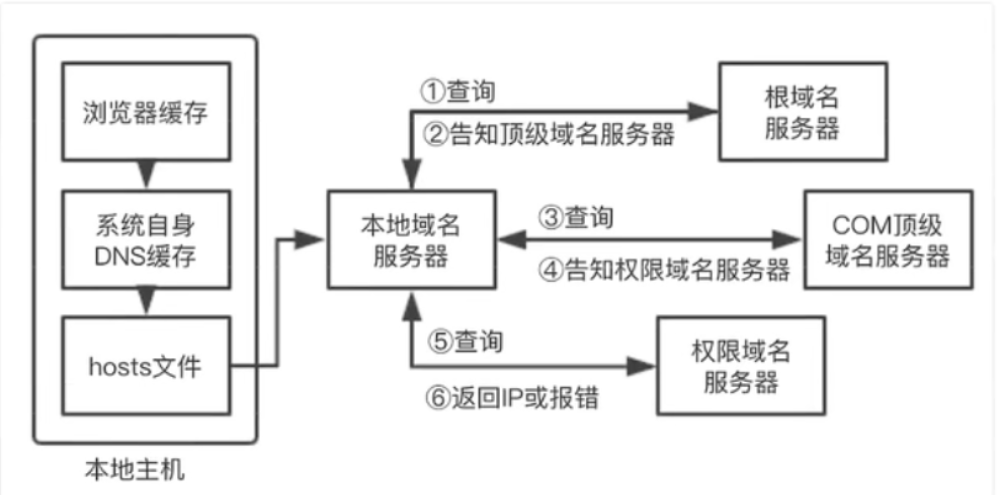
首先查询浏览器自身的DNS缓存,如果查到IP地址就结束解析,由于缓存时间限制比较大,一般只有1分钟,同时缓存容量也有限制,所以在浏览器缓存中没找到IP地址时,就会搜索系统自身的DNS缓存;如果还未找到,接着就会尝试从系统的 hosts文件中查找。 在本地主机进行的查询若都没获取到,接下来便会在本地域名服务器上查询。如果本地域名服务器没有直接的目标IP地址可供返回,则本地域名服务器便会采取迭代的方式去依次查询根域名服务器、COM顶级域名服务器和权限域名服务器等,最终将所要访问的目标服务器IP地址返回本地主机,若查询不到,则返回报错信息。
请求多个服务器时,需要向多个服务器索取资源时,可以先DNS预获取
建立 TCP 连接
- 三次握手确认连接,
- 数据包校验保证数据到达接收方
- 通过四次挥手断开连接。
发送 HTTP 请求
现在TCP连接建立完毕,浏览器可以和服务器开始通信,即开始发送 HTTP 请求。浏览器发 HTTP 请求要携带三样东西:请求行、请求头和请求体。
首先,浏览器会向服务器发送请求行,关于请求行, 我们在第一步就构建完了
// 请求方法是GET,路径为根路径,HTTP协议版本为1.1
GET / HTTP/1.1
2
结构很简单,由请求方法、请求URI和HTTP版本协议组成。
同时也要带上请求头,列举如下:
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
Cache-Control: no-cache
Connection: keep-alive
Cookie: /* 省略cookie信息 */
Host: www.baidu.com
Pragma: no-cache
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1
2
3
4
5
6
7
8
9
10
最后是请求体,请求体只有在POST方法下存在,常见的场景是表单提交。
网络响应
HTTP 请求到达服务器,服务器进行对应的处理。最后要把数据传给浏览器,也就是返回网络响应。
跟请求部分类似,网络响应具有三个部分:响应行、响应头和响应体。
响应行类似下面这样:
HTTP/1.1 200 OK
由HTTP协议版本、状态码和状态描述组成。
响应头包含了服务器及其返回数据的一些信息, 服务器生成数据的时间、返回的数据类型以及对即将写入的Cookie信息。
举例如下:
Cache-Control: no-cache
Connection: keep-alive
Content-Encoding: gzip
Content-Type: text/html;charset=utf-8
Date: Wed, 04 Dec 2019 12:29:13 GMT
Server: apache
Set-Cookie: rsv_i=f9a0SIItKqzv7kqgAAgphbGyRts3RwTg%2FLyU3Y5Eh5LwyfOOrAsvdezbay0QqkDqFZ0DfQXby4wXKT8Au8O7ZT9UuMsBq2k; path=/; domain=.baidu.com
2
3
4
5
6
7
响应完成之后怎么办?
这时候要判断Connection字段, 如果请求头或响应头中包含Connection: Keep-Alive,表示建立了持久连接,这样TCP连接会一直保持,之后请求统一站点的资源会复用这个连接。
否则断开TCP连接, 请求-响应流程结束。
# 第二阶段-解析算法
如果响应头中Content-Type的值是text/html,那么接下来就是浏览器的解析和渲染工作了。
解析部分,主要分为以下几个步骤:
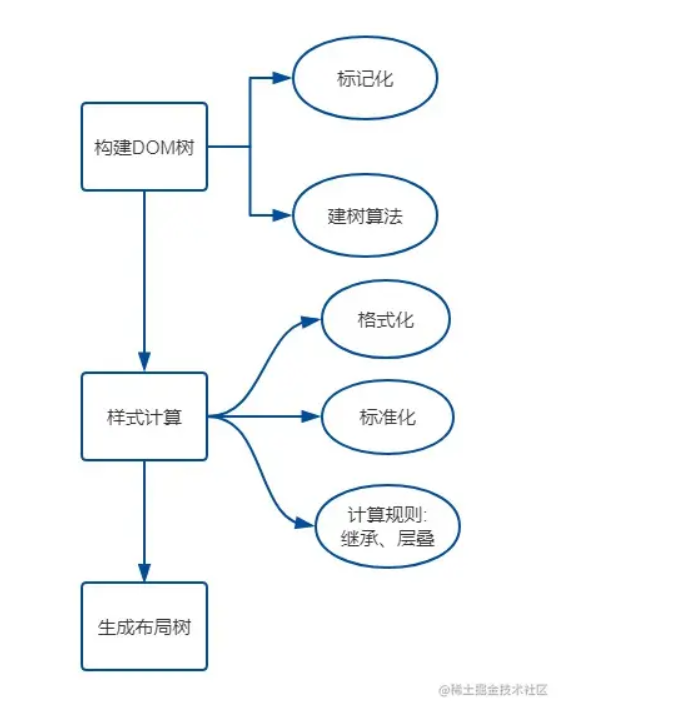
1、HTML解析,构建DOM树
字符编码:先将HTML的原始字节数据转换为文件指定编码的字符。
令牌化:然后浏览器会根据HTML规范来将字符串转换成各种令牌(如<html>、<body>、<p>这样的标签以及标签中的字符串和属性等都会被转化为令牌,每个令牌具有特殊含义和规则)。
生成节点对象:接着每个令牌都会被转换成定义其属性和规则的对象,即节点对象。
构建DOM树:最后将节点对象构建成树形结构,即DOM树。HTML标签之间有复杂的父子关系,树形结构刚好可以诠释这样的关系。

- 标记化
输入为HTML文本,输出为HTML标记,也成为标记生成器
遇到<, 状态为标记打开。
接收[a-z]的字符,会进入标记名称状态。
这个状态一直保持,直到遇到>,表示标记名称记录完成
- 建树
接收到标记生成器传来的html标签,这时候状态变为before html状态。同时创建一个HTMLHtmlElement的 DOM 元素, 将其加到document根对象上,并进行压栈操作。
接着状态自动变为before head, 此时从标记生成器那边传来body,表示并没有head, 这时候建树器会自动创建一个HTMLHeadElement并将其加入到DOM树中。
现在进入到in head状态, 然后直接跳到after head。
现在标记生成器传来了body标记,创建HTMLBodyElement, 插入到DOM树中,同时压入开放标记栈。
接着状态变为in body,然后来接收后面一系列的字符: Hello sanyuan。接收到第一个字符的时候,会创建一个Text节点并把字符插入其中,然后把Text节点插入到 DOM 树中body元素的下面。随着不断接收后面的字符,这些字符会附在Text节点上。
现在,标记生成器传过来一个body的结束标记,进入到after body状态。
标记生成器最后传过来一个html的结束标记, 进入到after after body的状态,表示解析过程到此结束。
2.CSS解析,构建CSSOM树
浏览器解析遇到<link>标签时,浏览器就开始解析CSS,像构建DOM树一样构建CSSOM树。下载和解析CSS 的工作是在预解析线程中进行的。这就是CSS 不会阻塞HTML解析的根本原因。
- 格式化样式表
浏览器是无法直接识别 CSS 样式文本的,因此渲染引擎接收到 CSS 文本之后第一件事情就是将其转化为一个结构化的对象,即styleSheets。
- 标准化样式属性
有一些 CSS 样式的数值并不容易被渲染引擎所理解,因此需要在计算样式之前将它们标准化,如em->px,red->#ff0000,bold->700等等。
这里的DOM是CSSOM,CSS 的加载和解析并不会阻塞 DOM Tree 的构建,因为 DOM Tree 和 styleSheets 是两个相互独立的结构。但是这个过程会阻塞页面渲染,也就是说在没有处理完 CSS 之前,文档是不会在页面上显示出来的
CSS计算规则
样式已经被格式化和标准化,接下来就可以计算每个节点的具体样式信息了。主要是继承和层叠两个规则。
每个子节点都会默认继承父节点的样式属性,如果父节点中没有找到,就会采用浏览器默认样式,也叫UserAgent样式,这就是继承
在计算完样式之后,所有的样式值会被挂在到window.getComputedStyle当中,也就是可以通过JS来获取计算后的样式
解析 Javascript 脚本
由于 Javascript 脚本可以通过 DOM API 和 CSSOM API 来操作 DOM 节点树和 CSS 规则树,因此该过程中会等待 JavaScript 运行完成才继续解析 HTML。
3.生成布局树(Layout Tree)
当我们生成 DOM 树和 CSSOM 树以后,就需要将这两棵树组合为渲染树。
当浏览器生成渲染树以后,就会根据渲染树来进行布局(也可以叫做回流)
渲染树,其实这还是 16 年之前的事情,现在 Chrome 团队已经做了大量的重构,已经没有生成Render Tree的过程了。而布局树的信息已经非常完善,完全拥有Render Tree的功能。
布局树生成的大致工作如下:
- 遍历生成的 DOM 树节点,并把他们添加到
布局树中。 - 计算布局树节点的坐标位置。
诸如head link style不会出现在布局树中是因为浏览器默认样式表为他们设置了display:none
# 渲染前置知识
浏览器中图层一般包含两大类:渲染图层(普通图层)以及复合图层
渲染图层,是页面普通的文档流。我们虽然可以通过绝对定位,相对定位,浮动定位脱离文档流,但它仍然属于默认复合层(根层叠上下文),共用同一个绘图上下文对象(GraphicsContext)。
复合图层,又称图形层。它会单独分配系统资源,每个复合图层都有一个独立的GraphicsContext。(当然也会脱离普通文档流,这样一来,不管这个复合图层中怎么变化,也不会影响默认复合层里的回流重绘)硬件加速就用在了这里
简单来理解就是拥有层叠上下文属性的元素会生成一个新的层叠上下文,每个层叠上下文对象都是一个渲染图层,渲染图层和复合图层是两个不同的概念,渲染图层更像是一个纯2维的概念,无论怎么层叠都最终归依于根层叠上下文。而某些特殊的渲染层会被提成为复合图层,复合图层则完全脱离根层叠上下文,相当于开辟新的位面,且由GPU合成。
创建复合图层
- 3D转换:translate3d,translateZ依此类推;
- video,canvas,iframe元件
- transform和opacity经由Element.animate();
- transform和opacity经由СSS过渡和动画;
- will-change;
- 有合成层后代同时本身 fixed 定位
- 拥有加速 CSS 过滤器的元素filter;
- 元素有一个z-index较低且包含一个复合层的兄弟元素(换句话说就是该元素在复合层上面渲染)
- 元素有一个包含复合层的后代节点(换句话说,就是一个元素拥有一个子元素,该子元素在自己的层里)
复合图层的作用
- 复合层的位图,会交由GPU合成。比CPU处理的要快
- 需要repaint时只需要repaint本身,不会影响到其他层。
- 对于 transform 和 opacity 效果,不会触发 layout 、layer和 paint,直接进入合成线程处理
- CPU 和 GPU 之间的并行性,可以同时运行以创建高效的图形管道。
层叠上下文:让HTML元素在2D平面堆叠出3D的视觉效果,根据层叠规则将哪个元素置于视觉最近处,哪个次之,以此类推。
如何形成层叠上下文:
- 文档根元素
- position不为初始值且z-index不为0或auto
- opacity属性值小于1
- flex布局元素
- will-change值设定为非初始值
- transform不为none
- filter不为none
布局(Layout):定位坐标和大小、是否换行、各种position/overflow/z-index属性等计算。
绘制(Paint):判断元素渲染层级顺序。
光栅化(Raster):将计算后的信息转换为屏幕上的像素。
位图:由称作像素(图片元素)的单个点组成的图片
# 第三阶段-渲染过程
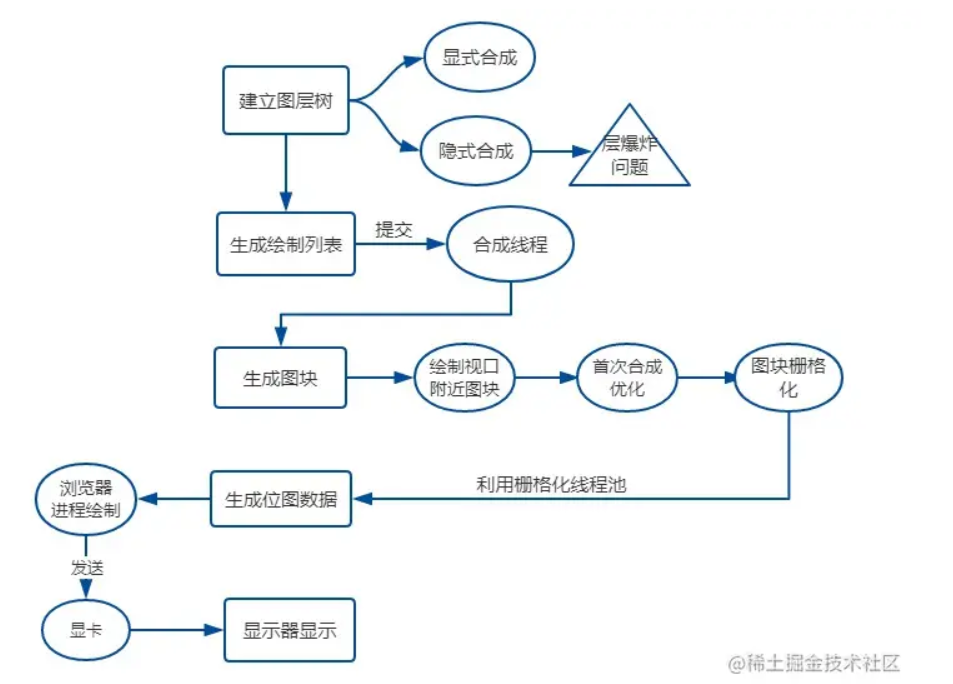
- 建立图层树(
Layer Tree)
页面并非单纯的平铺就可以了,实际上,页面还有许多复杂的3D变换、页面滚动、z-index排序等。为此,渲染引擎还需要为特定的节点生成专用的图层,浏览器在构建完布局树之后,还会对特定的节点进行分层,构建一棵图层树(Layer Tree)。
并不是布局树的每个节点都包含一个图层,如果一个节点没有对应的层,那么这个节点就从属于父节点的图层。
某些特殊的渲染层会被提升变为复合图层。复合图层拥有单独的 GraphicsLayer
什么情况下渲染引擎才会为特定的节点创建新的渲染图层呢?
1. 显式合成
拥有层叠上下文属性的元素
需要剪裁的地方。
比如一个div,你只给他设置 100 * 100 像素的大小,而你在里面放了非常多的文字,那么超出的文字部分就需要被剪裁。当然如果出现了滚动条,那么滚动条会被单独提升为一个图层。
- 隐式合成
接下来是隐式合成,简单来说就是层叠等级低的节点被提升为单独的图层之后,那么所有层叠等级比它高的节点都会成为一个单独的图层。
这个隐式合成其实隐藏着巨大的风险,如果在一个大型应用中,当一个z-index比较低的元素被提升为单独图层之后,层叠在它上面的的元素统统都会被提升为单独的图层,可能会增加上千个图层,大大增加内存的压力,甚至直接让页面崩溃。这就是层爆炸的原理
- 生成绘制列表
渲染引擎会对图层树中的每个图层进行绘制,也就是生成绘制指令。每个元素就是一个绘制块,一个绘制块就由好多条绘制指令组成。多个绘制块就组成一个绘制列表,也就是进入一个绘制队列,有先后顺序。
绘制操作是由渲染引擎中的合成线程(Compositor thread)来完成的。
- 生成图块并栅格化
有的图层可以很大,通过视口,用户只能看到页面的很小一部分,所以在这种情况下,要绘制出所有图层内容的话,就会产生太大的开销,而且也没有必要。 基于这个原因,合成线程会将图层划分为图块(tile),这些图块的大小有限制,比如长/宽必须是2的幂次方,最大不能超过2048或者4096等。
合成线程会按照视口附近的图块把它交给栅格化线程池生成位图。图块是栅格化执行的最小单位。渲染进程维护了一个栅格化的线程池,(没有启用硬件加速的浏览器)所有的图块栅格化都是在线程池内执行的。通常,栅格化过程都会使用 GPU 来加速生成,GPU 操作是运行在 GPU 进程中,如果栅格化操作使用了 GPU(对GPU而言并非图块而称之为纹理了),那么最终生成的位图被保存在 GPU 内存中(跨进程操作)。生成的位图最后发送给合成线程。
因为后面图块数据要进入 GPU 内存,考虑到浏览器内存上传到 GPU 内存的操作比较慢,即使是绘制一部分图块,也可能会耗费大量时间。针对这个问题,Chrome 采用了一个策略: 在首次合成图块时只采用一个低分辨率的图片,这样首屏展示的时候只是展示出低分辨率的图片,这个时候继续进行合成操作,当正常的图块内容绘制完毕后,会将当前低分辨率的图块内容替换。这也是 Chrome 底层优化首屏加载速度的一个手段。
合成线程可以给不同的光栅线程赋予不同的优先级(prioritize),进而使那些在视口中的或者视口附近的页面可以先被光栅化。为了响应用户对页面的放大和缩小操作,页面的图层(layer)会为不同的清晰度配备不同的图块。
- 显示器显示内容
栅格化操作完成后,合成线程会生成一个绘制命令,即"DrawQuad",并发送给浏览器进程。
浏览器进程中的viz组件接收到这个命令,根据这个命令,把页面内容绘制到内存,也就是生成了页面,然后把这部分内存发送给显卡
当某个动画大量占用内存的时候,浏览器生成图像的时候会变慢,图像传送给显卡就会不及时,而显示器还是以不变的频率刷新,因此会出现卡顿,也就是明显的掉帧现象。
# 总结
一个完整的渲染流程大致可总结为如下:
- 渲染进程将 HTML 内容转换为浏览器能够理解的 DOM 对象。
- 渲染引擎将 CSS 样式表转化为浏览器可以理解的 styleSheets,计算出 DOM 节点的样式。
- 创建布局树,并计算元素的布局信息。
- 对布局树进行分层,并生成分层树。分层的好处在于,将来某一个层改变后,仅会对该层进行后续处理,从而提升效率。
- 为每个图层生成绘制列表,并将其提交到合成线程。
- 合成线程将图层分成图块。
- 在光栅化线程池中将图块转换成位图。
- 合成线程发送绘制图块命令 DrawQuad 给浏览器进程。
- 浏览器进程根据 DrawQuad 消息生成页面,并显示到显示器上。
render tree -> 渲染元素 -> 图层 -> GPU 渲染 -> 浏览器复合图层 -> 生成最终的屏幕图像
可以 Chrome源码调试 -> More Tools -> Rendering -> Layer borders中看到,黄色的就是复合图层信息。
# 参考
深入浅出浏览器渲染原理 - 知乎 (zhihu.com) (opens new window)
(1.6w字)浏览器灵魂之问,请问你能接得住几个? - 掘金 (juejin.cn) (opens new window)
复合图层,渲染图层及性能优化 - 掘金 (juejin.cn) (opens new window)
10分钟看懂浏览器的渲染过程及优化 - 掘金 (juejin.cn) (opens new window)
(37条消息) 层叠上下文 渲染图层 复合图层(硬件加速)区别与联系_Free Joe的博客-CSDN博客 (opens new window)
(37条消息) 页面的渲染流程(Chrome)_Free Joe的博客-CSDN博客_页面渲染流程图 (opens new window)
(37条消息) 【精简版】浏览器渲染机制(完整流程概述)_hancao97的博客-CSDN博客 (opens new window)
